Learning to Synthesize Clifford Circuits
Our preprint Equivariant Reinforcement Learning for Clifford Quantum Circuit Synthesis, with Aleks Kissinger and Rob Cornish, is now on arXiv.
The short version: we trained a reinforcement-learning agent to synthesize Clifford quantum circuits. The agent is small enough to run in the browser, but it still finds optimal six-qubit circuits more than 99% of the time on the benchmark where exact optima are known.
Embedded seed 12345 instance
A 48-step random walk from the identity tableau, solved directly in the WebAssembly demo.
The Game
Quantum computation is typically described using the circuit model, where each gate corresponds to a primitive instruction on the device. Many circuits implement the same computation, and we wish to find the most efficient implementation of a given computation. Circuits are semantically equivalent if they correspond to the same $2^n \times 2^n$ unitary matrix. That exponential size is why the general task of unitary synthesis gets unpleasant very quickly. In fact, even the problem of deciding whether a given quantum circuit is close to the identity, up to global phase, is QMA-complete.
Clifford circuits are a special and extremely useful fragment. Thanks to the Gottesman-Knill theorem, instead of carrying around the full unitary, we can describe a Clifford operation using a compact $2n \times 2n$ binary symplectic matrix, often called a stabilizer tableau. (In this work, we omit the phase vector as it does not affect the entangling gate count and the phase vector can be easily recovered by tracking the Paulis.)
This matters in fault-tolerant architectures because Clifford operations are everywhere: error correction, lattice surgery, stabilizer measurements, and the Clifford scaffolding around non-Clifford resources such as magic states. Recent work on magic state cultivation shows that reducing entangling gate count is just as relevant as reducing $T$ count in the fault tolerant regime.
The embedded example above is exactly one of those synthesis games: it gives the learned policy a 6-qubit Clifford tableau and asks it to reduce the tableau. Abstractly, the task is:
- Start with a target binary matrix.
- Apply elementary Clifford gates $H_i$, $S_i$, and $CZ_{i,j}$.
- Each gate updates the tableau by a sparse local rule.
- Reach the identity, then reverse the moves to get a circuit for the original target.
The cost we care about most is the number of entangling $CZ$ gates. Single-qubit gates are not free, but on real hardware the two-qubit gates are usually substantially noisier. So the problem is not just to find a circuit: it is to find one with very few $CZ$ gates.
This is a bit like solving a Rubik’s cube. The states form a huge finite group, the gates are legal moves, and synthesis asks for a short path back to the solved state.
For six qubits, the Clifford group already has about $2.1 \times 10^{23}$ elements. The exact optimal database of Bravyi, Latone, and Maslov takes 2.1 TB of storage, and the paper reports that it required more than 300,000 CPU-hours to generate. Having an exact database of solutions is invaluable, but this method is intractable beyond $6$ qubits. Similarly, current SAT-solver-based methods cannot reliably synthesise fully random optimal 6 qubit Clifford circuits.
So the question is: can a learned heuristic get much of the benefit of exact search, without explicitly storing an optimal-synthesis database?
The Symmetry Trick
The main architectural idea is to build in the symmetry of the problem.
If I relabel all the qubits in a tableau, I have not changed the underlying synthesis problem. I have only renamed the wires. A good policy should notice this: relabeling the input tableau should simply relabel the probabilities it assigns to $H_i$, $S_i$, and $CZ_{i,j}$.
That property is called permutation equivariance. Instead of asking the neural network to learn every relabeled version of the same pattern from scratch, we make the architecture respect that symmetry by construction.

There is a theoretical reason why we can exploit these symmetries without losing optimality: for this symmetric Markov decision process, there exists an optimal policy with the same equivariance property. This is Proposition 3.1 of the paper, with a proof in Appendix A following the standard symmetry theory of finite MDPs.
For training, we use PPO via PufferLib. The curriculum is generated by random walks away from the identity tableau. Early on, the agent sees short walks; as it improves, the targets get farther away. This gives a dense enough learning signal without requiring a giant labelled dataset of optimal solutions.
What Happens On Six Qubits?
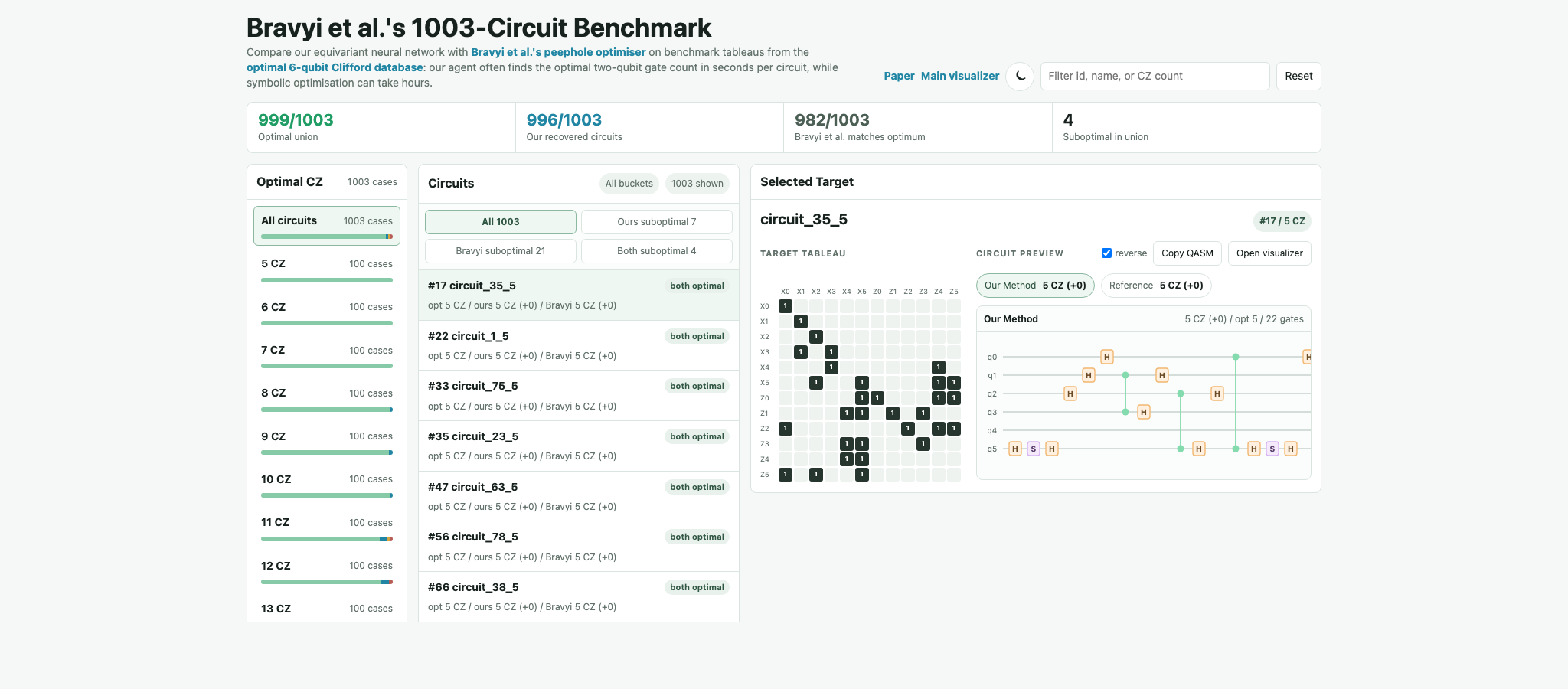
The cleanest test is the Bravyi et al. benchmark of 1003 six-qubit Clifford circuits, where exact optimal $CZ$ counts are known.
On this benchmark, our method solves every instance and matches the optimum on 995 996/1003 circuits, or 99.3%. The remaining cases are off by one $CZ$ gate. The policy-guided search reaches the previous state of the art after tens of minutes, and reaches 995 996/1003 exact recoveries after about three hours. By comparison, the previous search-heavy method recovered 982/1003 optima after 217 hours, with the remaining circuits consuming 576 hours without reaching the optimum. Combined with their method, we have recovered 999/1003 optimal circuits without using the unpublished 2TB database.
The policy network is small enough to run locally in WebAssembly, so inference does not require a remote service or GPU. The browser demo repeatedly applies this local policy to choose tableau-reducing moves.
Does It Scale?
The other nice feature is that the architecture is size-agnostic. The learned weights do not depend on a fixed number of qubits, so the same policy can be evaluated on larger tableaus without circuit splicing or reparameterizing the network.
The large-qubit results use the same policy after continued training on ten-qubit targets. Evaluated on unseen Clifford circuits up to 30 qubits, it returns lower average $CZ$ counts than Qiskit’s Aaronson-Gottesman and greedy Clifford synthesizers across a wide range of target difficulties. For example, at 30 qubits and 1024 initial Clifford gates, the learned synthesizer still solves all targets in that setting and uses 323.3 $CZ$ gates on average: 124.2 fewer than Qiskit’s greedy synthesizer and 460.1 fewer than Aaronson-Gottesman.
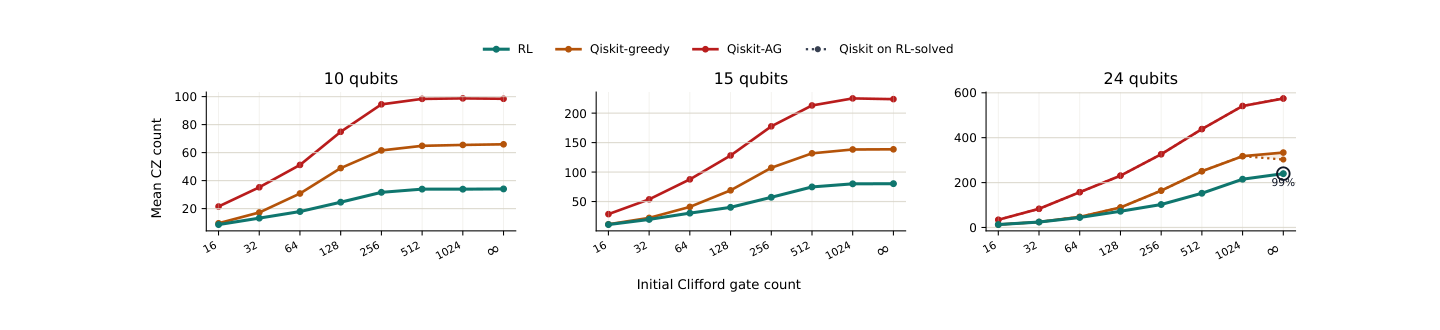
This shows that although the existing synthesis algorithms are “asymptotically optimal”, our method often produces circuits that are smaller by a factor of 2 or more. In rough terms, if each gate fails with probability $p$, the success rate of the overall optimised circuit goes from $(1 - p)^n$ to $(1 - p)^{n / 2}$. That is significant!
The result is a fast and compact model that is optimal on almost every benchmark instance at the largest size where optimal references are currently available, and still scales well beyond that. Hopefully we will turn this into a usable package soon.
Paper
The paper is on arXiv.
Please reach out if this model, benchmark data, or the symmetry-aware approach could be useful for your work. I would love to hear what people try with it.